
A web scraping tutorial using rvest on fivebooks.com
The purpose of this tutorial is to show a concrete example of how web scraping can be used to build a dataset purely from an external, non-preformatted source of data.
Our example will be the website Fivebooks.com, which I’ve been using for many years to find book recommendations. As explained on the website itself, Fivebooks asks experts to recommend the five best books in their subject and explain their selection in an interview. Their archive consists of more than one thousand interviews (i.e. five thousand book recommendations), and they add two new interviews every week.
Our objective will be to use R, and in particular the rvest package, to
gather the entire list of books recommended on Fivebooks, and see which
ones are the most popular.
Prerequisites
This tutorial assumes a very basic knowledge of HTML/CSS, which we’ll use to select elements in web pages. If you don’t know anything about those two languages, I’d strongly recommend spending an hour or two learning the basics. Not only will you be able to apply this tutorial, but HTML and CSS are very useful languages to understand for everyday tasks involving web pages.
Khan Academy has a very good interactive course on the subject: Intro to HTML/CSS: Making webpages. (In order to apply this tutorial you only really need to go through the Intro to HTML and Intro to CSS sections.)
Packages
rvest is part of the tidyverse. We’ll
also be using other packages, namely dplyr, stringr and
data.table. Of course if you haven’t installed those packages
previously, make sure to run
install.packages(c("rvest", "dplyr", "stringr", "data.table")) first.
library(rvest)
library(dplyr)
library(stringr)
library(data.table)
What do we want?
In order to get all the data we want and check the most popular books and authors on the website, we need to gather the following elements on each interview page:
- The general category of the interview (e.g. Philosophy or World & Travel)
- The subject of the interview (e.g. Emotional Intelligence)
- The titles of the recommended books (e.g. Wuthering Heights)
- The authors of those books (e.g. Emily Bronte)
- The URL of the page.
But in order to do this, we’ll also need to build a list of all the interviews on Fivebooks. There could be several ways to do this, including using Google’s indexing to look for pages from the fivebooks.com domain. But if you go to any interview page on Fivebooks, you’ll notice that after some scrolling, there are links to other interviews on the right. Every time we visit an interview page, we’ll check these links, and if any of them have not been visited yet, we’ll simply add them to our list of interviews to check next.
Let’s start coding!
We need to start from somewhere, so we’ll simply use a recent interview that appeared on the home page of Fivebooks when I wrote this tutorial.
to_be_visited <- "https://fivebooks.com/best-books/adam-smith-dennis-rasmussen/"
For now our vector to_be_visited only contains one page that we need
to look at. But as soon as we visit it, we’ll add to to_be_visited all
the recommended links given in the sidebar. Slowly this vector will
start including all the interviews on the website.
visited <- c()
As soon as a page has been visited, we’ll remove it from to_be_visited
and add it to visited. We’ll keep going from page to page in
to_be_visited like this, until all interviews have been checked, and
the sidebar recommendations stop adding new links to to_be_visited.
fivebooks_data <- list()
i <- 1
As we go from page to page, we’ll create a small data.frame for each
page with the information we need, and we’ll add it to a list called
fivebooks_data. At the end of the process, we’ll be able to use the
rbindlist function from the data.table package to elegantly merge
this list into one data.frame.
Our main loop will take the following form:
while (length(to_be_visited) > 0) {
# 1. Select the next page in to_be_visited
# 2. Gather the information we need from the interview
# 3. Put this information in a data.frame and insert it into fivebooks_data
# 4. Find the recommended links and add them to to_be_visited
# 5. Remove the page from to_be_visited and add it to visited
}
# Merge fivebooks_data into a data.frame
Instructions 1 and 5 are probably the easiest to write:
while (length(to_be_visited) > 0) {
# 1. Select the next page in to_be_visited
current_url <- to_be_visited[1]
# 2. Gather the information we need from the interview
# 3. Put this information in a small data.frame and insert it into the list
# 4. Find the recommended links and add them to to_be_visited,
# if they haven't been visited already!
# 5. Remove the page from to_be_visited and add it to visited
visited <- c(visited, current_url)
to_be_visited <- setdiff(to_be_visited, visited)
}
Gathering information from a webpage using rvest
In order to write instructions 2, 3, and 4, we’re going to have to use
rvest to scrape data from the page. Web scraping itself
isn’t terribly complicated, and rvest really makes the process very
easy in R.
For any given page, the first thing we’ll need to do is to read the HTML source:
page <- read_html(current_url)
From there, our object page contains all the source code, and
we simply need to navigate its contents and find the relevant pieces of
data. To navigate in the source, we’ll use HTML and CSS tags.
Fortunately modern web browsers give us tools to find the tags we need
without having to understand too much about the intrincate structure of
the page.
If you go to a page like the Adam Smith book interview, you can open the developer tools of your browser (Ctrl + Shift + I in Firefox and Chrome for Windows, and Cmd + Alt + I on a Mac). You can then use the element selector (step 1 below), and click on any element in the page to automatically select it in the HTML source (step 2).
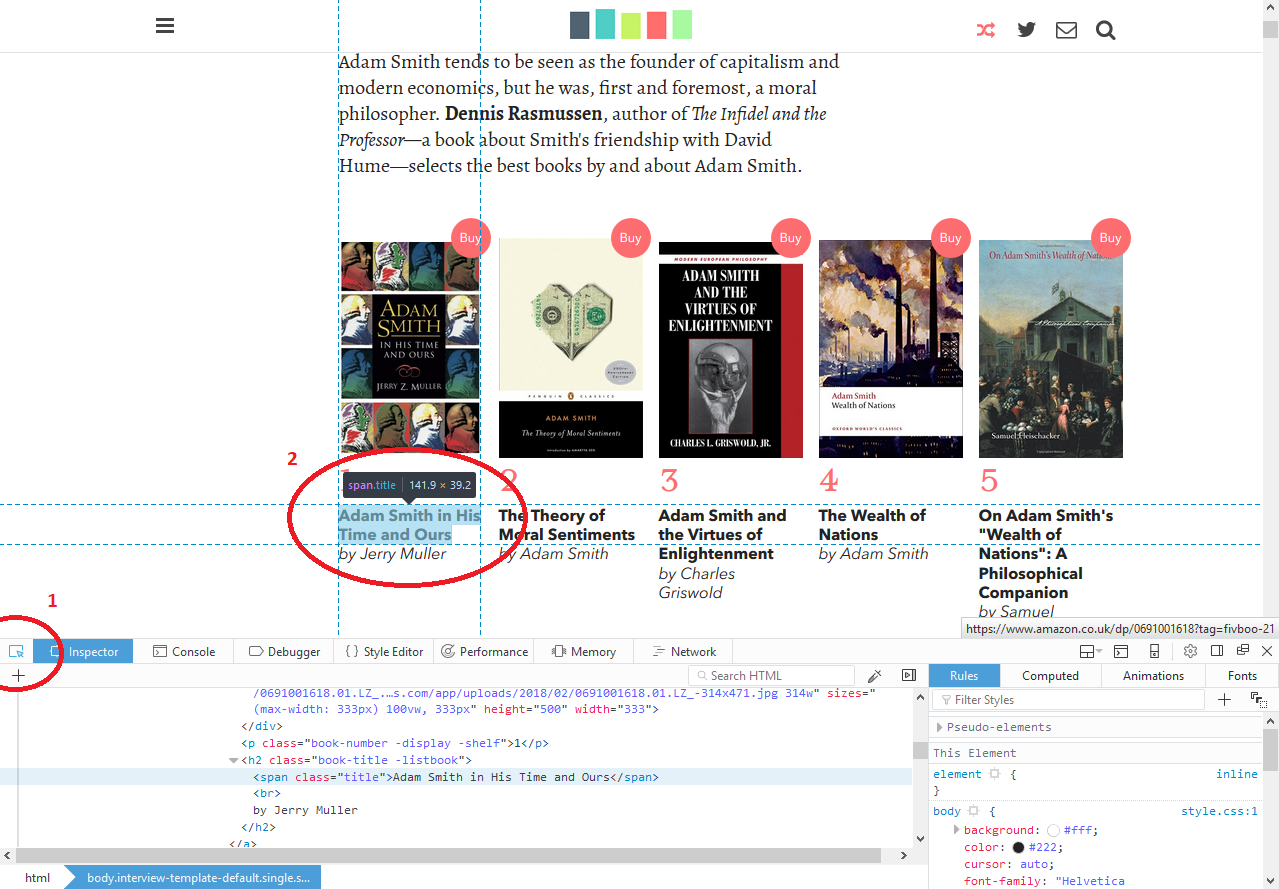
This tool is an excellent way to navigate the HTML source of a page, and find how to exactly select the data you need. By looking for the various elements we need in the page, we find that:
- The name of the category is mentioned at the top of each page, in a
CSS class called
interview-heading. - The subject of the interview is also at the top of the page, in an
element with class
subject. - The book names are written in elements with the class
title, inside a larger element with classinterview-page-bookshelf. Keep in mind that there are 5 book names to collect, so we’ll need to use the right function to collect all elements under this class, not just the first one. - Finally, the name of the author is also in the “bookshelf” (class
interview-page-bookshelf), in each element of classbook-title. These elements contain the name of the book, followed by the name of the author, such as “Adam Smith in His Time and Ours by Jerry Muller”.
Now, how do we select elements in a web page using rvest? Simply by
using the page object we created above, and the html_node
function to select an element based on its HTML tag or CSS class. CSS
classes should be prefixed with a dot. For example
page %>% html_node(".interview-heading") selects the first element of
the page with a CSS class of interview-heading. (This notation uses the pipe
operator
introduced by the magrittr package, and included in rvest.)
A couple more things to know:
- When multiple elements should be selected, such as for our books and
authors, we need to use
html_nodes(plural) instead ofhtml_node(singular) to return all elements, not just the first one. - We can specify a series of nested CSS classes in the function, in
which case
rvestwill select the element that uses the first CSS class, and then the element inside it that uses the second class, etc. For example,html_nodes(".interview-page-bookshelf .title")selects the element with a class ofinterview-page-bookshelf, and then looks for elements of classtitleinside.
Once we have selected the right elements, our last step is to extract
the text inside each element. Otherwise the element will contain its
HTML and CSS tags, which is not what we want. For this, we use the
html_text function and apply it to the selected elements. Thus, "<span class=\"subject\">Adam Smith</span>"
simply becomes "Adam Smith".
To summarise:
- We import the page using
read_html; - We select the elements using
html_nodeorhtml_nodes; - We extract the text using
html_text.
Finally, I’m using the str_replace function from the stringr package
to only extract the name of the author from the book-title elements.
This means for example that
"Adam Smith in His Time and Ours \n by Jerry Muller" becomes
"Jerry Muller".
This might seem like a lot of functions to use, but our code is actually not that long at this point:
while (length(to_be_visited) > 0) {
# 1. Select the next page in to_be_visited
current_url <- to_be_visited[1]
# 2. Gather the information we need from the interview
page <- read_html(current_url)
category <- page %>%
html_node(".interview-heading") %>%
html_text
subject <- page %>%
html_node(".subject") %>%
html_text
book <- page %>%
html_nodes(".interview-page-bookshelf .title") %>%
html_text
author <- page %>%
html_nodes(".interview-page-bookshelf .book-title") %>%
html_text %>%
str_replace(".* \n by ", "")
# 3. Put this information in a small data.frame and insert it into the list
# 4. Find the recommended links and add them to to_be_visited
# 5. Remove the page from to_be_visited and add it to visited
visited <- c(visited, current_url)
to_be_visited <- setdiff(to_be_visited, visited)
}
Storing the information
For each interview, we then create a small data.frame at step 3. This
includes the data from all of our variables: category, subject,
book, author and current_url.
This data.frame is stored in the fivebooks_data list that we created
before the loop, using the index i. After each interview, we increment
i by 1 so that the next interview is stored in the next space on the
list.
while (length(to_be_visited) > 0) {
# 1. Select the next page in to_be_visited
current_url <- to_be_visited[1]
# 2. Gather the information we need from the interview
page <- read_html(current_url)
category <- page %>%
html_node(".interview-heading") %>%
html_text
subject <- page %>%
html_node(".subject") %>%
html_text
book <- page %>%
html_nodes(".interview-page-bookshelf .title") %>%
html_text
author <- page %>%
html_nodes(".interview-page-bookshelf .book-title") %>%
html_text %>%
str_replace(".* \n by ", "")
# 3. Put this information in a small data.frame and insert it into the list
fivebooks_data[[i]] <- data.frame(category,
subject,
book,
author,
url = current_url,
stringsAsFactors = F)
i <- i + 1
# 4. Find the recommended links and add them to to_be_visited
# 5. Remove the page from to_be_visited and add it to visited
visited <- c(visited, current_url)
to_be_visited <- setdiff(to_be_visited, visited)
}
Adding recommandations
Let’s not forget that our scraping process is based on the idea of
gathering interview links, based on the recommendations in the sidebar.
Here we’ll need another bit of rvest code:
page %>% html_nodes(".related-item a") %>% html_attr("href").
This selects all links (HTML tags <a>) inside all elements with CSS
class related-item. After the links are selected, we use the
html_attr function to extract an HTML attribute of those links. Here
we’re interested in the href attribute, since it holds the actual URLs
of the recommended interviews.
We then add those links to the vector to_be_visited. Note that this
could potentially create duplicates in this vector, but since we later
use setdiff at step 5, all duplicates will be removed.
while (length(to_be_visited) > 0) {
# 1. Select the next page in to_be_visited
current_url <- to_be_visited[1]
# 2. Gather the information we need from the interview
page <- read_html(current_url)
category <- page %>%
html_node(".interview-heading") %>%
html_text
subject <- page %>%
html_node(".subject") %>%
html_text
book <- page %>%
html_nodes(".interview-page-bookshelf .title") %>%
html_text
author <- page %>%
html_nodes(".interview-page-bookshelf .book-title") %>%
html_text %>%
str_replace(".* \n by ", "")
# 3. Put this information in a small data.frame and insert it into the list
fivebooks_data[[i]] <- data.frame(category,
subject,
book,
author,
url = current_url,
stringsAsFactors = F)
i <- i + 1
# 4. Find the recommended links and add them to to_be_visited
recommended <- page %>%
html_nodes(".related-item a") %>%
html_attr("href")
to_be_visited <- c(to_be_visited, recommended)
# 5. Remove the page from to_be_visited and add it to visited
visited <- c(visited, current_url)
to_be_visited <- setdiff(to_be_visited, visited)
}
Putting the final touches
When I execute a web scraping script that will take a while to run, I like to know how far in the process it is, to make sure it is actually running and not hanging because of a bug. For this we’ll simply add a console message at the bottom of the loop, to tell us the subject of the interview that was just processed, how many pages have been visited so far, and how many are left to visit.
Finally, after the loop, we use the rbindlist function from the
data.table package to bind the rows of all the data.frames in our
fivebooks_data list.
Phew! That was a lot of explanations overall, but again the final code is not that long:
while (length(to_be_visited) > 0) {
# 1. Select the next page in to_be_visited
current_url <- to_be_visited[1]
# 2. Gather the information we need from the interview
page <- read_html(current_url)
category <- page %>%
html_node(".interview-heading") %>%
html_text
subject <- page %>%
html_node(".subject") %>%
html_text
book <- page %>%
html_nodes(".interview-page-bookshelf .title") %>%
html_text
author <- page %>%
html_nodes(".interview-page-bookshelf .book-title") %>%
html_text %>%
str_replace(".* \n by ", "")
# 3. Put this information in a small data.frame and insert it into the list
fivebooks_data[[i]] <- data.frame(category,
subject,
book,
author,
url = current_url,
stringsAsFactors = F)
i <- i + 1
# 4. Find the recommended links and add them to to_be_visited
recommended <- page %>%
html_nodes(".related-item a") %>%
html_attr("href")
to_be_visited <- c(to_be_visited, recommended)
# 5. Remove the page from to_be_visited and add it to visited
visited <- c(visited, current_url)
to_be_visited <- setdiff(to_be_visited, visited)
message(subject,
" - ",
length(visited), " pages visited",
" - ",
length(to_be_visited), " pages left to visit")
}
fivebooks_data <- rbindlist(fivebooks_data)
Let’s run it!
As the script starts running, we get the expected messages, telling us the interview being scraped, how many pages have been visited and how many are left to visit.
Adam Smith - 1 pages visited - 46 pages left to visit
Economic History - 2 pages visited - 49 pages left to visit
An Economic Historian's Favourite Books - 3 pages visited - 55 pages left to visit
The Lessons of the Great Depression - 4 pages visited - 54 pages left to visit
Globalisation - 5 pages visited - 66 pages left to visit
Entrepreneurship - 6 pages visited - 67 pages left to visit
Best Economics Books of 2017 - 7 pages visited - 66 pages left to visit
The Indian Economy - 8 pages visited - 70 pages left to visit
Saving Capitalism and Democracy - 9 pages visited - 69 pages left to visit
Financial Speculation - 10 pages visited - 68 pages left to visit
(...)
As expected, the number of pages “left to visit” quickly increases, as new interviews are found in the recommended links. The script takes several minutes to go through all the interviews, but finally ends with a total of 1,018 interview pages visited.
Analysing our results
I won’t go into details since this isn’t the goal of this tutorial, but by using dplyr we can easily tabulate counts on our newly created dataset, and find out what are the most recommended books and authors in more than 1,000 interviews on Fivebooks!
Most cited books overall:
fivebooks_data %>%
group_by(author, book) %>%
tally %>%
ungroup %>%
top_n(n = 10, wt = n)
## # A tibble: 18 x 3
## author book n
## <chr> <chr> <int>
## 1 Adam Smith The Wealth of Nations 5
## 2 Aldous Huxley Brave New World 5
## 3 Charles Darwin On the Origin of Species 5
## 4 Charles Dickens A Tale of Two Cities 5
## 5 Charlotte Brontë Jane Eyre 6
## 6 Clay Shirky Here Comes Everybody 5
## 7 Evelyn Waugh Scoop 7
## 8 George Eliot Middlemarch 5
## 9 Harper Lee To Kill a Mockingbird 5
## 10 Homer The Odyssey 6
## 11 John Buchan The Thirty-Nine Steps 5
## 12 John Stuart Mill On Liberty 6
## 13 Leo Tolstoy War and Peace 7
## 14 Mary Shelley Frankenstein 5
## 15 Michael Lewis Moneyball 6
## 16 Michael Lewis The Big Short 5
## 17 Richard Dawkins The Blind Watchmaker 5
## 18 Vasily Grossman Life and Fate 5
Most cited authors overall:
fivebooks_data %>%
filter(author != "") %>%
group_by(author) %>%
tally %>%
ungroup %>%
top_n(n = 10, wt = n)
## # A tibble: 10 x 2
## author n
## <chr> <int>
## 1 Charles Dickens 17
## 2 Evelyn Waugh 11
## 3 George Eliot 12
## 4 George Orwell 11
## 5 Jane Austen 11
## 6 Leo Tolstoy 12
## 7 Michael Lewis 12
## 8 Plato 11
## 9 Virginia Woolf 14
## 10 William Shakespeare 19
Most cited author by category:
fivebooks_data %>%
filter(author != "") %>%
group_by(category, author) %>%
tally %>%
top_n(n = 1, wt = n) %>%
print.data.frame()
## category author n
## 1 Art, Design and Architecture John Berger 4
## 2 Children's and Young Adult J R R Tolkien 3
## 3 Children's and Young Adult Jim Eldridge 3
## 4 Children's and Young Adult Raymond Briggs 3
## 5 Children's and Young Adult Rudyard Kipling 3
## 6 Economics, Business & Investing John Maynard Keynes 7
## 7 Economics, Business & Investing Michael Lewis 7
## 8 Fiction William Shakespeare 10
## 9 Food & Cooking Elizabeth David 5
## 10 Health & Lifestyle Augustus Napier and Carl Whitaker 2
## 11 Health & Lifestyle Barry Prizant and Tom Fields-Meyer 2
## 12 Health & Lifestyle Benjamin Bloom 2
## 13 Health & Lifestyle Colette 2
## 14 Health & Lifestyle Cynthia Kim 2
## 15 Health & Lifestyle Jay Haley 2
## 16 Health & Lifestyle John Holt 2
## 17 Health & Lifestyle Leo Tolstoy 2
## 18 Health & Lifestyle Michael Lewis 2
## 19 Health & Lifestyle Michelle Sutton (editor) 2
## 20 Health & Lifestyle Ned Hayes 2
## 21 Health & Lifestyle Norman Doidge 2
## 22 Health & Lifestyle Stephen Jay Gould 2
## 23 Health & Lifestyle Susan Senator 2
## 24 Health & Lifestyle William Clark Styron 2
## 25 Health & Lifestyle William Lederer and Don Jackson 2
## 26 Health & Lifestyle William Shakespeare 2
## 27 History Isaiah Berlin 5
## 28 History Vasily Grossman 5
## 29 History William Shakespeare 5
## 30 Language Dorothea Brande 2
## 31 Language John Felstiner 2
## 32 Language Nicholas Ostler 2
## 33 Language Stephen King 2
## 34 Law & Constitutions Albert Camus 1
## 35 Law & Constitutions Alexis de Tocqueville 1
## 36 Law & Constitutions Clarence Thomas 1
## 37 Law & Constitutions Diego Gambetta 1
## 38 Law & Constitutions Donald Shell 1
## 39 Law & Constitutions Geoffrey Robertson 1
## 40 Law & Constitutions George V Higgins 1
## 41 Law & Constitutions Henry Adams 1
## 42 Law & Constitutions Jeff Shesol 1
## 43 Law & Constitutions JL Austin 1
## 44 Law & Constitutions Joan Biskupic 1
## 45 Law & Constitutions Linda Greenhouse 1
## 46 Law & Constitutions Marcel Proust 1
## 47 Law & Constitutions Peter Facey 1
## 48 Law & Constitutions Peter Norman 1
## 49 Law & Constitutions Richard H. Rovere 1
## 50 Law & Constitutions Sadakat Kadri 1
## 51 Law & Constitutions Seth Stern and Stephen Wermiel 1
## 52 Law & Constitutions Stephen Wall 1
## 53 Law & Constitutions Vernon Bogdanor 1
## 54 Literary Nonfiction & Biography Samuel Taylor Coleridge 3
## 55 Literary Nonfiction & Biography Virginia Woolf 3
## 56 Mathematics & Science Richard Dawkins 7
## 57 Mind & Psychology Steven Pinker 4
## 58 Music & Drama Anne Ubersfeld 3
## 59 Music & Drama Antoine Vitez 3
## 60 Music & Drama Jacques Copeau 3
## 61 Music & Drama Louis Jouvet 3
## 62 Nature & Environment Callum Roberts 3
## 63 Nature & Environment Douglas Adams 3
## 64 Nature & Environment Elizabeth Kolbert 3
## 65 Philosophy Plato 10
## 66 Politics & Society George Orwell 6
## 67 Religion Raymond Brown 2
## 68 Sports, Games & Hobbies Simon Kuper 3
## 69 Technology Clay Shirky 2
## 70 Technology Julian Dibbell 2
## 71 Technology Neal Stephenson 2
## 72 Technology Sherry Turkle 2
## 73 Uncategorized Gary Kinder 1
## 74 Uncategorized Jonathan Harr 1
## 75 Uncategorized Nathaniel Philbrick 1
## 76 Uncategorized Susan Griffin 1
## 77 Uncategorized Susan Orlean 1
## 78 World & Travel Amartya Sen 4